Imagine training life-saving AI models without ever risking a single patient’s privacy. This isn’t science fiction—it’s happening right now with synthetic data.

Table of Contents
- The Healthcare AI Paradox
- What Exactly Is Synthetic Data?
- The Game-Changing Applications
- The Technology Behind the Magic
- From Lab to Reality: A Practical Implementation
- Real-World Success Stories
- The Regulatory Landscape
- The Tools Powering the Revolution
- Challenges and Considerations
- Looking Ahead: The Future of Healthcare AI
- The Bottom Line
The Healthcare AI Paradox
Healthcare AI has a problem. To save lives, we need data—lots of it. To train an AI system that can detect early signs of cancer or predict patient outcomes, we need access to thousands, sometimes millions, of patient records. But here’s the catch: that same data is so sensitive that sharing it could destroy lives through privacy breaches.
It’s like trying to teach someone to drive without ever letting them see a car. The traditional approach has been to lock down real patient data behind layers of security and regulation—necessary protections that have inadvertently created a bottleneck for medical innovation.
Enter synthetic data: the breakthrough that’s solving this seemingly impossible puzzle.
What Exactly Is Synthetic Data?
Think of synthetic data as a master artist creating a painting that captures all the essential elements of a landscape without copying any real place. Synthetic data is algorithmically generated to mirror the statistical patterns, relationships, and characteristics of real healthcare data—but it contains zero actual patient information.
It’s not just scrambled or anonymized real data. It’s entirely artificial data that behaves like real data when used to train AI models. The result? We can develop and test healthcare AI systems without ever touching sensitive patient information.

The Game-Changing Applications
1. Training AI Without the Wait
Traditionally, getting approval to use real patient data for AI training could take months or years. With synthetic data, researchers can start training models immediately while parallel approval processes run for validation data.
2. Filling the Gaps
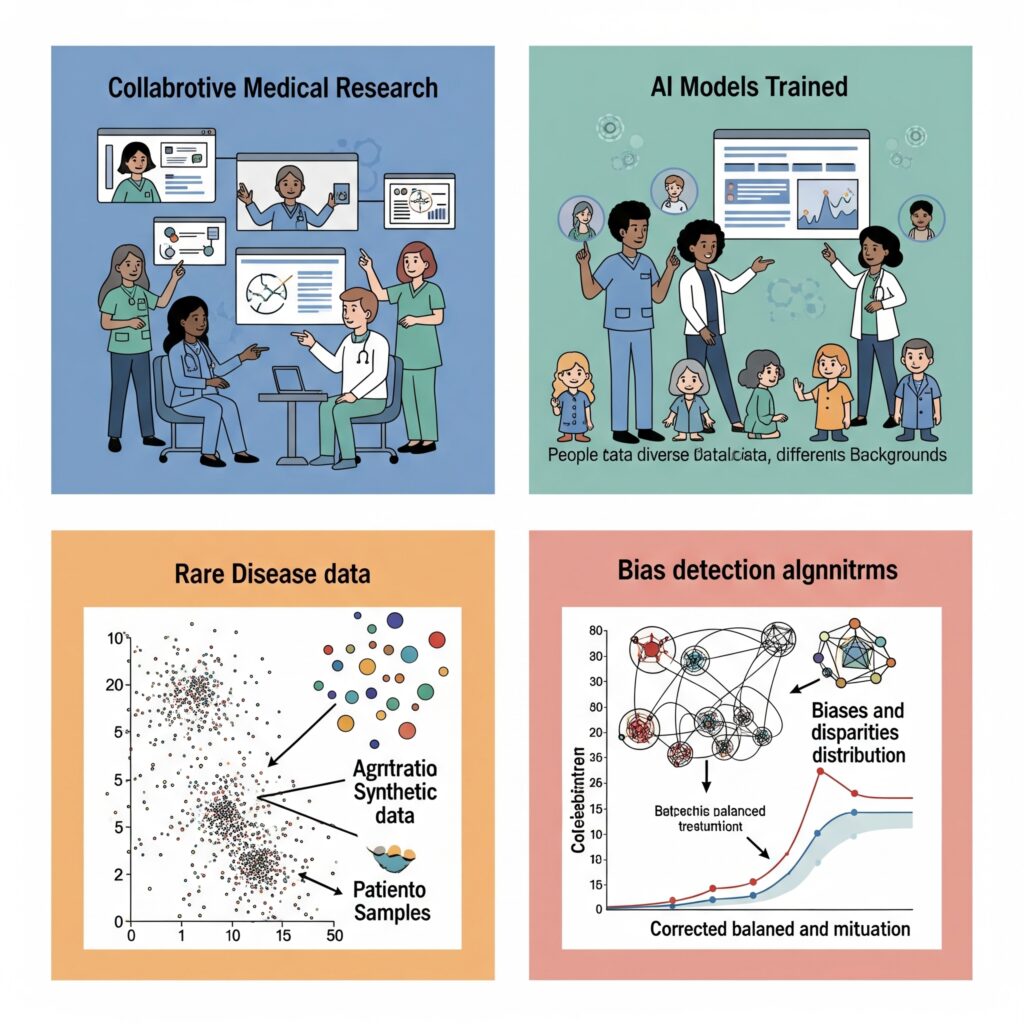
Rare diseases affect millions of people worldwide, but individually, they often lack enough data to train robust AI models. Synthetic data can generate additional samples that preserve the statistical signature of these conditions, enabling AI development for underserved populations.
3. Breaking Down Silos
Hospitals and research institutions can now collaborate freely. Instead of sharing sensitive patient data (which often requires complex legal agreements), they can share synthetic datasets that enable joint research without privacy concerns.
4. Bias Detection and Mitigation
By generating diverse synthetic populations, researchers can identify when their AI models are biased toward certain demographics and actively work to create more equitable healthcare AI.
The Technology Behind the Magic
Creating high-quality synthetic healthcare data isn’t trivial. Here are the key approaches making it possible:
Advanced Generation Models
- CTGAN (Conditional Tabular GAN): Handles the mixed data types common in healthcare—everything from numerical age values to categorical disease classifications
- TVAE (Tabular Variational AutoEncoder): Provides more stable data generation with better handling of complex relationships
- Copulas: Statistical methods that capture how different health conditions tend to occur together
Privacy-First Design:
Ensuring Patient Confidentiality utilizes sophisticated techniques to protect patient privacy. Here’s a deeper look at the privacy-preserving methodologies being utilized:
- Differential Privacy:
- Adds carefully calibrated “noise” to the data generation process or calculation results.
- This noise obscures individual contributions, preventing data from being traced back to a specific person.
- Provides a mathematical guarantee of privacy, ensuring that individuals cannot be identified even with analysis of the synthetic data.
- PATE-GAN (Private Aggregation of Teacher Ensembles Generative Adversarial Network):
- Employs a “teacher-student” approach.
- Multiple “teacher” models are trained on different subsets of real data.
- A “student” model mimics the teachers’ output without accessing the original data directly.
- This prevents extraction of individual details while preserving overall data characteristics.
- Advanced Hashing:
- Converts data into a fixed-size string of characters (a hash).
- Makes it extremely difficult to link synthetic records back to real patients.
- Specialized algorithms make tracing data back to an individual very difficult, even with computational resources.
- Provides robustness against re-identification attacks, ensuring data anonymity.
Quality Assurance
The robustness and reliability of synthetic datasets are paramount for their effective application in healthcare AI. To ensure high-quality output, every synthetic dataset undergoes rigorous and comprehensive testing, spanning several critical dimensions:
- Statistical Fidelity:A fundamental aspect of quality assurance is verifying the statistical fidelity of the synthetic data. The aim is to ascertain whether the synthetic data accurately mirrors the underlying patterns and relationships found in the real data. Key comparisons may include distributions, means, standard deviations, correlations, and other relevant statistical measures.
- Machine Learning Utility:Ultimately, the value of synthetic data lies in its utility for training machine learning models. Therefore, a crucial evaluation step is assessing the machine learning utility of the synthetic dataset. This assessment typically involves training AI models on the synthetic data and comparing their performance with models trained on the corresponding real data. Metrics such as accuracy, precision, recall, F1-score, and area under the ROC curve are utilized to evaluate model performance.
- Privacy Risk Assessment: In the context of healthcare, privacy is a paramount concern. Thus, a comprehensive privacy risk assessment is an indispensable component of the quality assurance process. This assessment seeks to evaluate the potential for re-identification of individuals from the synthetic data.
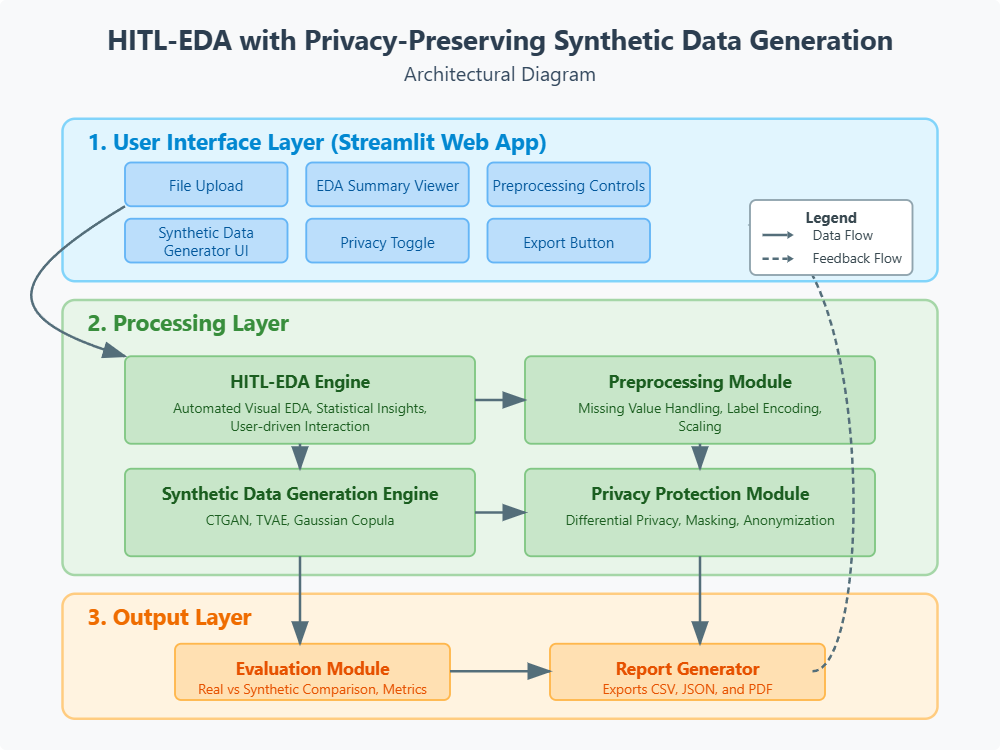
From Lab to Reality: A Practical Implementation
Let’s walk through how a real synthetic data system works in practice, diving deeper into the engineering complexities and architectural decisions that make these systems production-ready:
Step 1: Secure Data Ingestion & Infrastructure
The foundation of any synthetic data system is robust, secure data ingestion. Healthcare organizations can’t simply dump patient data into a system—every byte must be protected from the moment it enters the pipeline.
Secure and robust data ingestion is crucial for synthetic data systems in healthcare. Multi-layer security includes encryption (TLS 1.3, field-level, zero-knowledge, homomorphic), real-time validation detects anomalies and quality issues, and federated learning enables decentralized model training across institutions while preserving data sovereignty.
Step 2: Intelligent Data Profiling & Relationship Discovery
Understanding Healthcare Data Relationships: Delving deeper into healthcare data relationships transcends simple statistical measures. It necessitates uncovering temporal patterns such as seasonal shifts in illness prevalence and the natural course of disease development.
Translating Clinical Reasoning into Data Models:Additionally, it’s crucial to translate clinical reasoning into data models that faithfully represent actual medical workflows. This involves managing a wide array of data types, including electronic health records (EHRs) and medical imaging, each with its unique format and complexity.
Addressing Data Biases:Moreover, it’s essential to pinpoint and detail any inherent biases within the data, as these can significantly impact the accuracy and fairness of synthetic data generation processes.A thorough examination of these intricate relationships is vital for leveraging healthcare data effectively and responsibly.
Step 3: Advanced Privacy Engineering
Privacy is integral, not an add-on. It’s built into the system’s core.
Differential Privacy at Scale: Sophisticated privacy budget management across queries and users. Tracks expenditure, recycles budgets, and adjusts parameters based on data sensitivity.
Multi-Party Computation Protocols: Enables collaborative research with secure computation without sharing raw data. Uses cryptographic protocols, secure channels, and distributed trust.
Privacy-Preserving Record Linkage: Matches patients across datasets using techniques like Bloom filters and secure hashing without revealing identities.
Continuous Privacy Monitoring: Real-time risk assessment, monitoring for re-identification, inference, and inversion attacks. Automated alerts for privacy thresholds..
Step 4: Sophisticated Synthetic Generation
This is where the magic happens, though the engineering challenges are significant.
Hybrid Model Architectures: Production systems combine GANs for complex learning, VAEs for stable generation, and statistical methods for specific data types. Intelligent routing optimizes model usage.
Clinical Constraint Enforcement: Generated data undergoes medical validity checks with hundreds of rules. Machine learning models add further validation.
Longitudinal Coherence: Temporal modeling ensures realistic patient journeys. Treatments align with diagnoses, and medical history remains consistent.
Adaptive Generation Parameters: Parameters adjust based on use cases, prioritizing statistical fidelity or specific conditions.
Step 5: Comprehensive Validation & Quality Assurance
Validation ensures real-world performance, not just statistical similarity.
Multi-Dimensional Fidelity Assessment: Synthetic data is evaluated across numerous dimensions, including distributions, correlations, and complex relationships. Advanced methods measure similarity.
Predictive Model Benchmarking: Machine learning models are trained on real and synthetic data, and their performance on clinical tasks is compared using benchmark suites.
Clinical Expert Review Integration: Domain experts assess synthetic data for clinical plausibility by reviewing synthesized patient cases.
Adversarial Testing: Re-identification attacks are used to test the data’s resilience. Only data that withstands these attacks is approved.
Continuous Quality Monitoring: Post-deployment, the system tracks synthetic data performance in real applications and identifies improvement areas.
Step 6: Enterprise-Grade Deployment & Governance
Moving from prototype to production requires advanced architecture.
API-First Architecture: Systems offer APIs for downloads, streaming, and federated queries, with built-in rate limiting, authentication, and authorization.
Comprehensive Audit Systems: All data interactions are logged for regulatory compliance and usage analytics.
Data Lineage and Provenance: Records track data generation, privacy parameters, and validation tests, essential for regulations and reproducibility.
Integration with Existing Healthcare IT: Systems must integrate with hospital systems, data warehouses, and trial platforms, supporting various formats, HL7 FHIR standards, and legacy compatibility.
Scalable Infrastructure: Systems must handle massive datasets, scale horizontally across cloud infrastructure, and optimize resources for training and generation.
This end-to-end implementation represents a sophisticated engineering effort that bridges cutting-edge research with practical healthcare needs. The complexity reflects the critical importance of getting synthetic healthcare data right—these systems will ultimately support life-saving medical research and AI development.
Real-World Success Stories
The impact is already being felt across the healthcare industry:
Roche Pharmaceuticals used synthetic patient populations to simulate drug responses across diverse demographics, reducing their time-to-clinical-trial by 24%. This acceleration could mean life-saving treatments reaching patients months earlier. Read here
NHS England deployed synthetic hospital data to test resource allocation models during the COVID-19 pandemic, enabling rapid policy decisions without compromising patient privacy.
Harvard’s AI Lab trained COVID-19 mortality prediction models using synthetic electronic medical records, achieving over 90% of the performance they would have gotten with real data—but with zero privacy risk. Read here
The Regulatory Landscape
Synthetic data operates in a complex regulatory environment:
- GDPR Compliance: Since synthetic data contains no real personal information, it sidesteps many GDPR restrictions while still enabling valuable research
- HIPAA Considerations: Properly generated synthetic data doesn’t contain Protected Health Information (PHI), making it easier to share and collaborate
- FDA Recognition: The FDA is increasingly recognizing synthetic data as a valid tool for certain types of medical device validation
The Tools Powering the Revolution
Several frameworks are making synthetic data accessible:
- Synthetic Data Vault (SDV): An open-source platform that’s become the go-to solution for many researchers
- TimeGAN: Specialized for time-series medical data, preserving the temporal patterns crucial for patient monitoring
- SynthCity: A modular platform specifically designed for healthcare applications
Challenges and Considerations
Like any powerful technology, synthetic data comes with challenges:
The Overfitting Risk: If not properly designed, synthetic data generation models can memorize real data, potentially creating privacy vulnerabilities.
Bias Amplification: Synthetic data can inadvertently amplify existing biases in the original data, requiring careful monitoring and mitigation strategies.
Regulatory Evolution: While synthetic data offers promising solutions, regulations are still evolving to address this new paradigm.
Quality Assurance: Ensuring synthetic data maintains the complexity and nuance of real healthcare data requires sophisticated validation methods.
Looking Ahead: The Future of Healthcare AI
Synthetic data represents more than just a technical solution—it’s a fundamental shift in how we approach healthcare AI development. By decoupling AI training from direct patient data access, we’re creating a future where:
- Innovation accelerates without compromising privacy
- Collaboration flourishes across institutional boundaries
- Equity improves as AI models can be trained on diverse, representative populations
- Costs decrease as the barriers to AI development are lowered
The Bottom Line
Synthetic data isn’t replacing real healthcare data—it’s augmenting it. It’s creating a pathway for responsible AI development that respects patient privacy while advancing medical science. As we stand on the brink of an AI revolution in healthcare, synthetic data may well be the key that unlocks the full potential of artificial intelligence to save and improve lives.
The question isn’t whether synthetic data will transform healthcare AI—it’s how quickly we can harness its power responsibly. For healthcare providers, researchers, and tech companies, the message is clear: the future of healthcare AI is synthetic, and that future is now.
References
- Y. Li and W. Li, “Data Distillation for Text Classification,” arXiv preprint, 2021.
- A. Maekawa, N. Kobayashi, K. Funakoshi, and M. Okumura, “Dataset Distillation with Attention Labels for Fine-tuning BERT,” in Proc. ACL, Toronto, Canada, Jul. 2023, pp. 119-127.
- A. Maekawa, S. Kosugi, K. Funakoshi, and M. Okumura, “DiLM: Distilling Dataset into Language Model for Text-level Dataset Distillation,” in Proc. NAACL Findings, Mexico City, Mexico, Jun. 2024, pp. 3138-3153.
- Y. Tao et al., “Textual Dataset Distillation via Language Model Embedding,” in Proc. EMNLP, 2024.
- H. Lu et al., “UniDetox: Universal Detoxification of Large Language Models via Dataset Distillation,” in Proc. ICLR, 2025.
- X. Cai, C. Wang, and Q. Long et al., “Knowledge Hierarchy Guided Biological-Medical Dataset Distillation for Domain LLM Training,” in Proc. DASFAA, 2025.
- D. Medvedev et al., “New Properties of the Data Distillation Method When Working With Tabular Data,” in Proc. AIST, 2020.
- Z. Liu et al., “Dataset Condensation for Time Series Classification via Dual Domain Matching,” in Proc. KDD, 2024.
- J. Ding and Z. Liu et al., “CondTSF: One-line Plugin of Dataset Condensation for Time Series Forecasting,” in Proc. NeurIPS, 2024.
- H. Miao et al., “Less is More: Efficient Time Series Dataset Condensation via Two-fold Modal Matching,” in Proc. VLDB, 2025.